Log e trace
RocketAiFlow usa monitoraggio basato su OpenTelemetry per monitorare quello che succede durante l'esecuzione dei workflow, il comportamento telefonico, le azioni API, i servizi runtime e l'infrastruttura di supporto.
Log e trace vanno letti insieme. I log mostrano il dettaglio dell'evento: cosa è successo, quando è successo, quale servizio lo ha prodotto e quali metadati sono associati. I trace mostrano il percorso: come la stessa operazione attraversa i servizi e dove iniziano latenza, errori o comportamenti inattesi.
Perché usarli insieme
In un'investigazione di produzione, una singola riga di log spesso non basta. Anche un trace senza il contesto dei log può essere troppo astratto. Usarli insieme dà agli operatori una vista più chiara su:
- eventi di avvio chiamata ed esecuzione campagna
- cambi di stato di trunk, endpoint e telefonia
- comportamento di function e azioni API
- latenza dei servizi e percorsi di errore
- metadati come campagna, contatto, operazione, risultato, nome servizio e identificativi trace
Grafana Drilldown
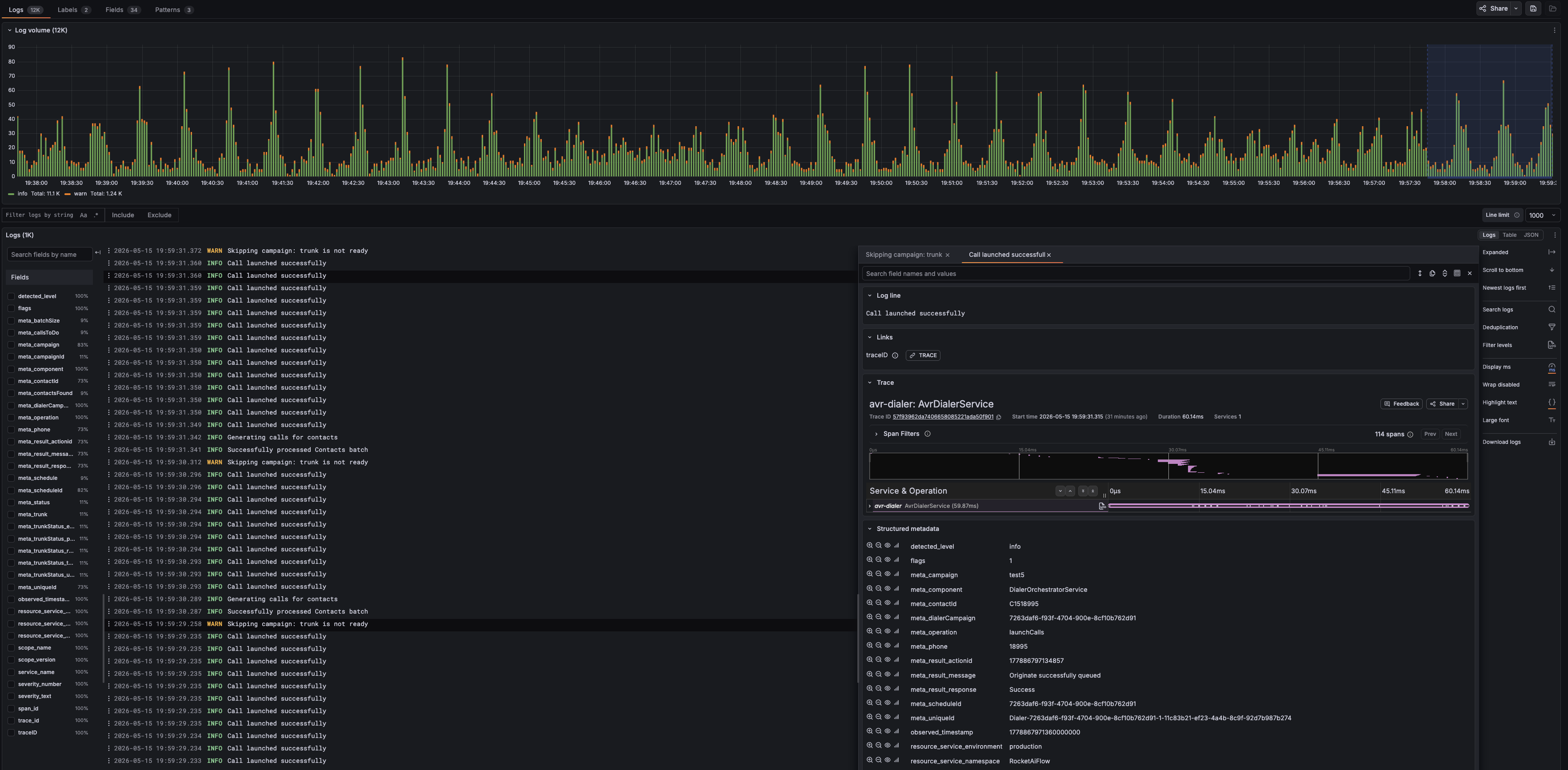
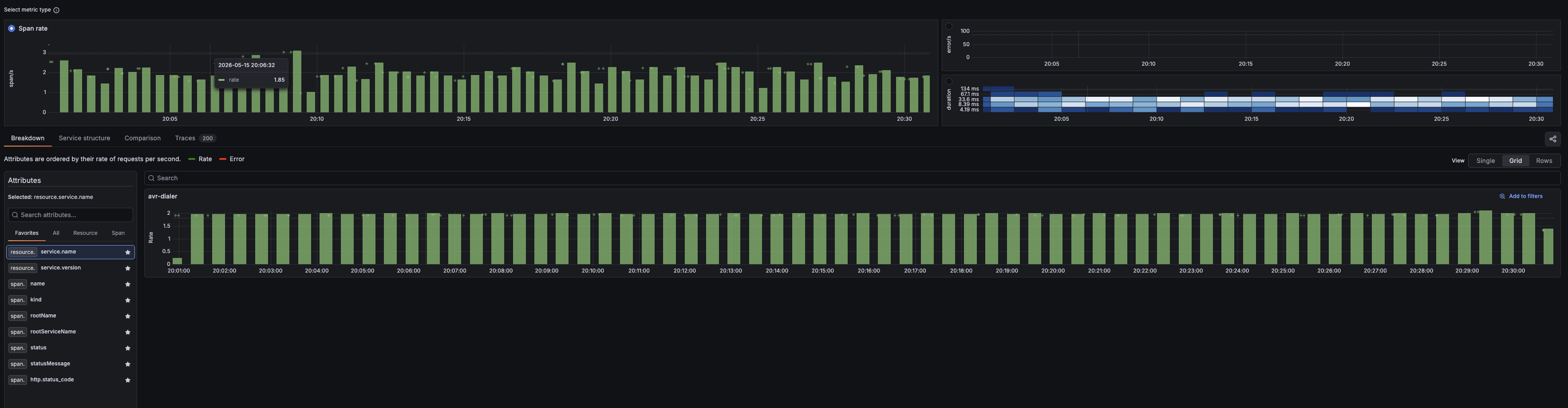
Grafana Drilldown è la vista avanzata per analizzare log e trace. Usala quando una dashboard mostra che qualcosa è cambiato e devi filtrare, cercare e correlare gli eventi che spiegano il problema.
- filtrare i log per livello, servizio, campi, label e intervallo temporale
- cercare dentro messaggi di log e metadati strutturati
- aprire un evento di log e seguire il trace ID collegato
- rivedere span, operazioni dei servizi, timing e metadati strutturati
- correlare log e trace senza saltare tra strumenti separati
Quando usare log e trace
- una chiamata, campagna, transfer o azione API si comporta in modo diverso dal previsto
- una dashboard mostra una variazione ma non l'evento che l'ha causata
- il problema attraversa più servizi o integrazioni esterne
- timing, latenza o retry devono essere spiegati con evidenza concreta
- il troubleshooting richiede evidenza prima di modificare prompt, routing, campagne o functions
Percorso pratico di investigazione
- Parti dal sintomo in monitoring, call record o campaign analytics.
- Restringi l'intervallo temporale e route, campagna, contatto, trunk o servizio coinvolto.
- Usa i log per trovare il dettaglio dell'evento e i metadati strutturati.
- Segui il trace ID quando il problema attraversa più servizi o richiede analisi dei tempi.
- Torna al livello responsabile con evidenza: telefonia, logica workflow, runtime, azione API o dati.